.gitattributes, cortex and github language analysis
Whats the problem?
Lets take a scenario. You’ve been doing a great job of splitting out your dotnet services into individual repositories. You’ve been adopting infrastructure as code and have even decided go down the route of the cloud developer kit, embracing the typescript goodness. Everything is sunshine and roses, yet whenever you look at github you see this.
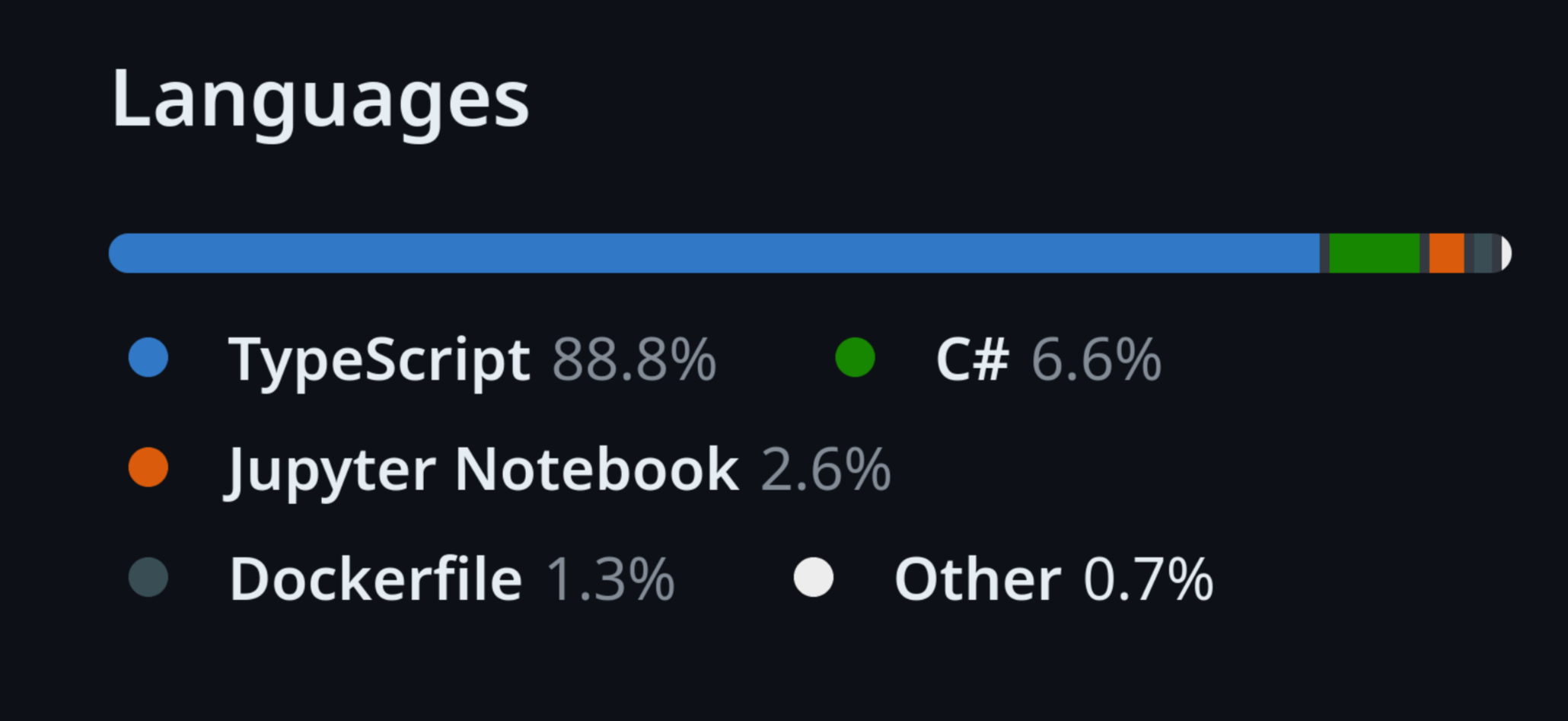
Annoying right? But no big deal. It’s just a UI element you can quickly ignore and a natural result of having a whole bunch of typescript files managing your per service infra. You then log into your fancy new developer portal and realize that this little UI niggle is stalking you.
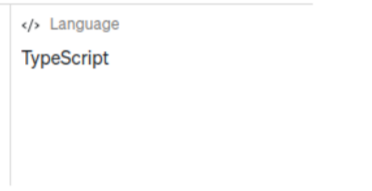
Which also means all those fancy queries you wanted to run based on the language identified by git aren’t going to work.
Suddenly the UI niggle has become a bit of a pain and something has to be done about it.
A bit of background
The Linguist
Before diving into how to solve this, lets take a quick look at the background of what’s happening.
Github uses the linguist library for both file language identification and syntax highlighting.
This is what enables that snazzy little language breakdown. The challenge comes, naturally, from when you have a large amount of files in the repo which aren’t related to the actually code you’ve been writing. This can most commonly be seen with vendored libraries in a repo, but also crops up in situations like we described above where there’s a bunch of supporting code to help deploy what you’ve been working on.
The API
So we know how the language identification works now and where it can trip up, but how do tools which query github get that information ? Generally they’ll be building on top of the list repository languages API endpoint.
This returns an object with each identified language as a key, with a value showing the number of bytes of code written in that language. A lot of the time what folk care about when querying this API is the language with the most bytes.
Which in our example, is typescript.
Despite the fact that the code we care about definitely isn’t
How to solve it
To see an example of this, you can go here
The solution for this is pretty trivial, with the caveat that it will hide the languages you specify from the UI element and the API call.
Linguist comes with a set of overrides which you can use to control it’s behavior. These get added into a .gitattributes in the root directory.
There’s a few options in the overrides depending on your use case. While ours is a bunch of auto-generated and vendored code, another could be documentation which is stored alongside the source which is potentially generated from the comments in the code.
Ultimately regardless of what you use you will get the same result, excluding the directory, path, file, extension (or whatever other git pattern matching you use) from the linguist stats.
For this example we’ll go with vendored which gives us a .gitattributes file along these lines:
nonsense/** linguist-vendoredAnd that’s it. Linguist will now ignore the nonsense folder. The Github API will respond as we’d want. We can make use of Cortex’s Query Language to start doing weird and wonderful things based on identified language. Most importantly, at least for me, I get a little bit more calm whenever I see the github UI element reporting what I’d want it to report.
A final note on .gitattributes
As a final passing note which I might write more on in the future, it is worth taking a look at the .gitattributes file link earlier. There’s a lot more power with it than just overriding linguist settings. It’s one of those things you rarely need but can be super handy on occasion.